SED - The Stream EDitor - Part I
Ce document est une introduction à la pratique et à l'utilisation de l'éditeur de flux "SED", qui essaie de couvrir certaines fonctionnalités assez méconnues, pour ne pas dire "
quasi inconnues", qui font de "SED" un outil indispensable dans la boîte à outils de tout Linuxien désireux de se rompre aux maniements et aux arcanes du traitement de fichiers via une console et un shell.
Sommaire part I
 Partie II
Partie III
Partie II
Partie III
Présentation
Sed signifie "Stream EDitor" autrement dit "éditeur de flux", et plus précisément "éditeur de flux orienté ligne". De par sa conception et son mode de fonctionnement, Sed est un éditeur non-interactif.
Tout comme l'éditeur "ed" -dont il est issu et que l'on trouve toujours dans les distributions actuelles- et contrairement aux autres éditeurs tels que vi, emacs, Nedit, Xedit, etc., qui eux fonctionnent sur une page complète de texte affiché à l'écran, Sed agit sur une seule ligne à la fois.
À ses débuts l'éditeur "ed" s'est vu doté d'une commande travaillant sur son flux d'entrée standard plutôt que sur un fichier, capable d'afficher toutes les lignes contenant une expression régulière. Cette commande dont la syntaxe s'écrit sous la forme "g/re/p" (
global/regular expression/print) donnera naissance à l'utilitaire "grep". Quelques temps après une nouvelle implémentation d'une version de "ed" vit le jour, travaillant uniquement sur le flux d'entrée standard tout en tirant ses instructions d'un fichier de scripts. Cette version fut baptisée Stream EDitor, plus connue sous le nom de "Sed".
L'éditeur de flux Sed lit les lignes d'un ou plusieurs fichiers depuis l'entrée standard, enchaine des commandes lues elles aussi depuis l'entrée standard sous forme d'expressions (
commandes d'édition) ou depuis un fichier texte (
script), et écrit le résultat du traitement sur la sortie standard.
On pourrait résumer le mécanisme de fonctionnement de Sed de cette façon :
- lecture d'une ligne sur le flux d'entrée (une ligne étant délimitée par un caractère de saut de ligne);
- traitement de la ligne en fonctions des diverses commandes lues;
- affichage (ou non) du résultat sur la sortie standard (écran);
- passage à la ligne suivante.
Notons que pour sélectionner la ou les ligne(s) sur la(les)quelle(s) elles doivent opérer, les commandes acceptent des numéros de lignes, des intervalles, ou encore des expressions régulières (
notées RE ou regex).
Introduction
Sed prend ses instructions (
commandes) depuis la ligne de commandes ou depuis un fichier (
script) et applique chaque instruction, dans l'ordre de leur apparition, à chaque ligne en entrée. Une fois que chaque instruction a été appliquée à la 1ère ligne d'entrée, la ligne est affichée (
ou non, selon ses besoins) sur la sortie standard (
l'écran, ou redirigée dans un fichier) et Sed procède alors à la lecture et au traitement de la ligne suivante et ainsi de suite jusqu'à la fin du fichier d'entrée (
à moins qu'il ne rencontre une instruction de sortie explicite).
Ce mécanisme est appelé "cycle". On entend par cycle le traitement des données présentes dans l'espace de travail par l'ensemble des commandes qui composent le script. Par défaut un cycle correspond à :
- L'ajout dans l'espace de travail d'une ligne en entrée (une ligne étant délimitée par le caractère fin de ligne (\n))
- Normalement l'espace de travail doit être vide, à moins qu'une commande "D" ait achevé le cycle précédent (auquel cas un nouveau cycle repartira avec les données restantes dans l'espace de travail).
- Sed appliquera alors les commandes (issues d'un script ou depuis la ligne de commande) concernant les données présentes dans l'espace de travail, séquentiellement, et une fois arrivé en fin de script, copiera les données traitées vers la sortie standard, sauf indication contraire avec l'option "-n" et effacera l'espace de travail. Toutes les données envoyées vers la sortie standard ou un fichier, sont suivies par un caractère de fin de ligne (\n).
- Chargement d'une nouvelle ligne ou sortie si la fin du fichier est atteinte.
Essayons d'illustrer à l'aide d'un organigramme le fonctionnement de Sed à travers un script tout simple qui efface les lignes vides d'un fichier et celles ne comportant qu'un seul caractère "dièse" (#) en début de ligne. Pour ce faire voici un exemple de fichier comportant pour la circonstance quelques lignes vides, quelques dièses seuls dont un en retrait et non pas en début de ligne et deux lignes avec plusieurs dièses à la suite :.
Le fichier :
#
#
#
##
# Ceci est un commentaire
# En voici un autre
#
#
#
###
# Et un autre
#
#
# Et un dernier pour la route
#
Le script en lui même est relativement simple. Le voici sur une seule ligne :
sed -e '/^$/d;/^#$/d'
et dans un fichier script :
#! /bin/sed -f
/^$/d # on efface les lignes vides
/^#$/d # on efface les lignes ne comportant qu'un seul caractère "dièse"
#+ se trouvant en début de ligne et rien d'autre derrière
Et l'organigramme :

Syntaxe
Syntaxe générale
sed [-options] [commande] [<fichier(s)>]
sed [-n [-e commande] [-f script] [-i[.extension]] [l [cesure]] rsu] [<commande>] [<fichier(s)>]
Syntaxe d'une commande
L'adressage d'une ou plusieurs lignes par quelques moyens que ce soit est facultatif pour n'importe quelle commande
[adresse[,adresse]][!]commande[arguments]
Par contre un ensemble de commandes peuvent être appliquées à une ligne ou intervalle de lignes en les entourant par des accolades.
[adresse[,adresse]]{
commande1
commande2
commande3
}
Notez que ces commandes peuvent être accolées sur une seule ligne à condition d'être séparées par un point virgule (;).
[adresse[,adresse]]{commande1; commande2; commande3}
Adressage
Sed peut adresser directement une ligne (
ou un intervalle) par son numéro de ligne ou par la mise en correspondance avec une expression régulière ciblant un motif (
patron/modèle) défini.
Un point d'exclamation (!) après un numéro de ligne, un motif ou une expression régulière exclura cette ligne (
ou intervalle) du traitement à effectuer.
Cet adressage peut s'effectuer sous les formes suivantes :
num
début~pas
- Toutes les n lignes (pas) en partant de début.
$
- La dernière ligne du dernier fichier fourni en entrée, ou de chaque fichier si les options "-i" ou "-s" ont été spécifiées
sed -n '$ p' fich.txt
sed -ns '$ p' fich*
/exp/
- Toutes les lignes mises en correspondance avec l'expression régulière exp
\#exp#
- Toutes les lignes mises en correspondance avec l'expression régulière exp en précisant d'utiliser comme délimiteur le caractère "#" (dièse) en lieu et place du délimiteur par défaut.
num1,num2
- Toutes les lignes comprises entre num1 et num2. Si num2 venait à être inférieur à num1, seul num1 est affiché
/exp1/,/exp2/
- Toutes les lignes comprises entre exp1 et exp2, y compris les lignes contenant exp1 et exp2. Si l'intervalle contenant les 2 expressions se répète plusieurs fois, Sed appliquera les instructions à chaque intervalle successivement. Si toutefois exp2 n'est pas trouvée, les instructions sont appliquées à chaque ligne en partant de exp1 et ce jusqu'à la fin du fichier.
num,/exp/
/exp/,num
- Toutes les lignes comprises entre un numéro de ligne et une expression régulière (ou l'inverse). Dans "num,/exp/", si toutefois exp n'est pas trouvée, les instructions sont appliquées à chaque ligne en partant de num et ce jusqu'à la fin du fichier. Dans "/exp/,num", si num est inférieur au numéro de ligne correspondant à exp, seul la ligne contenant exp est affichée.
sed -n '2,/commentaire2/ p' fich2.txt
sed -n '/commentaire1/,8 p' fich2.txt
Les options (paramètres)
Sed accepte des options (
paramètres) en entrée, peu nombreuses, et dont les plus usitées sont "-n", "-e" et "-i".
-n, --quiet, --silent
- Demande implicite de ne pas afficher l'état de la mémoire principale (mémoire tampon). À l'intérieur d'un script, la notation se fera de cette façon "#n" (un signe dièse suivi du caractère "n") et devra se trouver sur la 1ère ligne du script.
-e
script, --expression=
script
- Permet d'enchaîner plusieurs commandes à la suite
-f
fichier-script, *--file=
fichier-script
- Lecture des commandes depuis le fichier désigné
-i[
SUFFIXE], --in-place[
=SUFFIXE]
- Édition en place du fichier. Offre aussi la possibilité de faire une sauvegarde en y ajoutant une extension (-i.BAK)
--posix
- Désactiver toutes les extensions GNU.
-r, --regexp-extended
- Utilisation de la syntaxe des expressions régulières étendues (ERE)
-s,
--separate
- Si plusieurs fichiers sont fournis en entrée, les traiter un à un plutôt que comme une seule et même page
-u,
--unbuffered
- Charger des quantités minimales de données depuis les fichiers d'entrée et libérer les tampons de sortie plus souvent
--help
- Afficher cette aide et sortir
--version
- Afficher les informations de version du logiciel et sortir
Les commandes
Nous allons voir dans les chapitres qui suivent les commandes utilisées par Sed. Autant certaines d'entre-elles peuvent paraitre simples d'utilisation et communes dans leur ensemble, autant pour quelques autres, peu connues il est vrai, leur utilisation et implémentation au sein de scripts Sed peuvent s'avérer plus difficile au point de vue syntaxe et mise en uvre, mais donner une autre dimension à cet outil relégué au rang de simple filtre...
Certaines commandes admettent un adressage multi-lignes (
intervalle) alors que d'autres ne tolèrent qu'une seule adresse voir même aucune pour une minorité. Ces particularités seront notifiées pour chaque commande.
Les commandes basiques 1
Sont regroupées dans ce chapitre les commandes les plus connues de l'éditeur Sed et relativement simples d'emploi.
#
Commentaire (
Aucune adresse autorisée)
- Le caractère # (dièse) commence un commentaire et ce jusqu'à la fin de la ligne. Il peut se trouver sur la même ligne qu'une commande.

Si les deux premiers caractères d'un script sed sont "#n", l'option "-n" (
no-autoprint) est alors forcée. Donc si votre script doit impérativement débuter par une ligne de commentaire commençant par la lettre "n" minuscule, veillez à utiliser un "N" majuscule ou d'insérer un espace entre le dièse (#) et le "n".
q
quit
quitter (
une adresse autorisée)
- Quitte sed sans procéder à aucune autre commande ni évaluer une autre entrée. La ligne courante contenue dans la mémoire principale est affichée à moins que l'option "-n" ait été employée.
d
delete
effacer (
intervalle d'adresse autorisée)
- Efface l'enregistrement courant et démarre un nouveau cycle.
p
print
affichage (
intervalle d'adresse autorisée)
- Affiche à l'écran l'enregistrement courant (l'espace de travail). Elle n'efface pas l'espace de travail et ne modifie pas non plus le déroulement du script. Cette commande est toujours employée conjointement avec l'option "-n", sans quoi l'affichage de la ligne est dupliquée. (Préférer la seconde forme mieux adaptée du fait que le script s'achève dès que le motif ou la ligne rencontré est affichée sur la sortie standard sans continuer à parcourir le reste du fichier)
sed -n '3p' fich.txt
sed -n '3{p;q}' fich.txt
n
next-line
ligne suivante (
intervalle d'adresse autorisée)
- Remplace l'enregistrement courant dans l'espace de travail par la ligne suivante sans entamer un nouveau cycle. La ligne remplacée quant à elle est envoyé sur la sortie standard.
{ ... }
commandes groupées (
intervalle d'adresse autorisée)
- L'emploi d'accolades permet de regrouper certaines commandes à effectuer sur une adresse ou une plage d'adresses. Il est inutile de les protéger par un caractère backslash comme c'est le cas pour l'emploi des expressions régulières indiquant un nombre de répétitions.
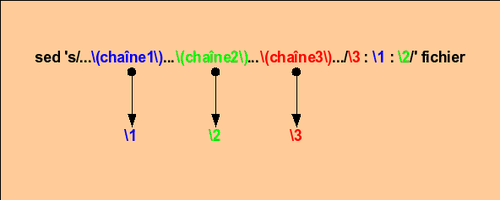
s
substitution
La commande de substitution (
intervalle d'adresse autorisée)
- La commande de substitution "s" est sans nul doute la commande la plus utilisée du filtre sed. Sa syntaxe est fort simple :
- Son principe de base est très simple lui aussi : si un motif correspondant à la chaîne mise en évidence par le modèle ou l'expression régulière est trouvé, le substituer par la chaîne de remplacement, en tenant compte des drapeaux éventuels si présents.
- Dans le mécanisme de substitution il faut distinguer deux parties souvent référencées par LHS (Left Hand Side = côté gauche) qui correspond à la chaîne recherchée et RHS (Right Hand Side = côté droit) correspondant à la chaîne de remplacement.
- Autant la partie gauche (recherche) accepte la syntaxe des BRE (Basic Regular Expression, expressions régulières basiques), la partie droite (remplacement) quant à elle n'accepte que trois valeurs pouvant être interpolées :
- le caractère & (esperluette)
- les références arrières \1 (de 1 à 9)
- les options \U,\u,\L,\l et \E
Pour interpréter littéralement une esperluette (&) ou un anti-slash (\) il faut les préfixer par un anti-slash :
\& ou \\
flags
Les drapeaux ou attributs
La commande de substitution (s) peut être suivie d'aucun ou de plusieurs drapeaux/attributs (
flags en anglais). Certaines combinaisons ne peuvent être associées comme l'attribut "g" (
global) et une nième occurrence (
N) ce qui relèverait d'une incohérence absolue. Dans le même ordre d'idée, l'attribut "w" doit être le dernier de la liste.
g
global
- Effectue le remplacement de toutes les occurrences mises en correspondance par le motif ou l'expression régulière
echo "AAAAA" | sed 's/A/B/'
BAAAA
echo "AAAAA" | sed 's/A/B/g'
BBBBB
N
nième occurrence
- Remplace uniquement la nième occurrence mise en correspondance par le motif ou l'expression régulière
echo "AAAAA" | sed 's/A/B/3'
AABAA
p
print (affichage)
- Si une substitution a eu lieu, alors afficher l'enregistrement courant. Nécessite la présence de l'option "-n".
$ var="ligne1\nligne2\nligne3\nligne4\nligne5"
$ echo -e "$var"
ligne1
ligne2
ligne3
ligne4
ligne5
$ echo -e "$var" | sed '3 s/e3/e n° 3/'
ligne1
ligne2
ligne n° 3
ligne4
ligne5
$ echo -e "$var" | sed -n '3 s/e3/e n° 3/'
$ echo -e "$var" | sed '3 s/e3/e n° 3/p'
ligne1
ligne2
ligne n° 3
ligne n° 3
ligne4
ligne5
$ echo -e "$var" | sed -n '3 s/e3/e n° 3/p'
ligne n° 3
w
fichier - Write (écriture dans un fichier)
- Si une substitution a eu lieu, alors écrire l'enregistrement courant dans le fichier spécifié. Un seul espace est accepté entre l'attribut "w" et le nom du fichier.
$ var="ligne1\nligne2\nligne3\nligne4\nligne5"
$ echo -e "$var" | sed -n '3 s/e3/e n° 3/pw fich.out'
e
evaluate (évaluation)
- Permet de faire exécuter une commande par le shell et d'en substituer le résultat avec le motif mis en correspondance, uniquement si une correspondance a été établie
Exemple 1 :
$ echo $var
ligne1\nligne2\nligne3\nligne4\nligne5\nligne6\nligne7\nligne8\nligne9
$ echo $A
Bonjour
$ echo -e "$var" | sed 's/.*5/echo '$A'/e'
ligne1
ligne2
ligne3
ligne4
Bonjour
ligne6
ligne7
ligne8
ligne9
$
Exemple 2 :
$ cat plop
0x00000000 0 root 777
0x00000000 65537 user1 600
0x00000000 98306 user1 600
$ echo -e "$var" | sed 's/.*5/cat plop/e'
ligne1
ligne2
ligne3
ligne4
0x00000000 0 root 777
0x00000000 65537 user1 600
0x00000000 98306 user1 600
ligne6
ligne7
ligne8
ligne9
$
Discussion en rapport sur le forum
I
case-Insensitive
- Permet d'ignorer la casse lors de la mise en correspondance du motif
$ echo "BonJouR" | sed 's/bONjOUr/Salut/'
BonJouR
$ echo "BonJouR" | sed 's/bONjOUr/Salut/I'
Salut
M
- Le modificateur M pour la mise en correspondance d'expressions régulières est une nouvelle extension de GNU Sed qui a pour effet de mettre en correspondance le caractère ^ et le caractère $ (en plus de leur comportement d'origine) respectivement avec une chaîne vide après une nouvelle ligne, et une chaîne vide avant une nouvelle ligne. Il y avait déjà les caractères spéciaux \` et ' (en mode basique ou étendu des expressions régulières) qui mettaient en correspondance le début et la fin du tampon. M étant lui multi-lignes.
Pour essayer de faire plus simple, en tant normal l'espace de travail contient une ligne lue en entrée. D'autres lignes peuvent être ajoutées à l'espace de travail à travers l'emploi des commandes comme N, G, x, etc. Toutes ces lignes dans l'espace de travail sont séparées par le caractère de fin de ligne "\n" mais sont vues par Sed comme une seule et même ligne dont le début commence avant la 1ère ligne et se terminant à la fin de la dernière ligne. Avec le flag "M" chaque caractère représentant le début (^) et la fin ($) de ligne reprend si on peut dire ainsi, son sens initial et fait correspondre le début et la fin de ligne à chaque ligne se trouvant dans l'espace de travail.
Voici un exemple illustrant l'emploi du flag "M" :
1er cas :
$ echo -e "foo\nbar" | sed 'N;s/^.*$//'
$
Dans ce 1er cas, ^ et $ pointent le début et la fin du tampon qui après l'application de la commande "N" contient "foo\nbar$", et l'expression régulière matche donc tout ce qui se trouve entre les deux caractères symbolisant le début (^) et la fin ($) sans tenir compte du caractère représentant la fin de ligne "\n"
2ème cas :
$ echo -e "foo\nbar" | sed 'N;s/^.*$//M'
bar
$
Dans ce 2nd cas, ^ et $ pointent le début et la fin de la 1ère ligne dans le tampon, qui comme précédemment après l'application de la commande "N" contient "foo\nbar$", mais à la différence que l'expression régulière matche uniquement les caractères se trouvant avant le caractère fin de ligne "\n"
3ème cas :
$ echo -e "foo\nbar\nfoobar\nbarfoo" | sed -e ':boucle; N; $! b boucle; s/^.*$//M3'
foo
bar
barfoo
$
Dans ce 3ème cas, le tampons après l'exécution de la commande "N" (
à l'intérieur d'une boucle ayant pour effet de charger l'intégralité des lignes dans le tampon), ressemble à "foo\nbar\nfoobar\nbarfoo$" et la substitution ne s'applique qu'à la 3 ème ligne matérialisée par le caractère "\n".
Voici 2 autres exemples :
Le 1er :
$ echo -e "foo\nfoo\nfoo\nbar\nfoo" | sed 'N;/bar$/s/^/>/Mg;P;D'
foo
foo
>foo
>bar
foo
$
Dans l'exemple ci-dessus, 2 lignes sont chargées dans l'espace de travail, si la fin du tampon ne finit pas par "bar", alors la 1ère ligne du tampon est affichée (P), puis effacée (D), et on reprend l'exécution du script avec le chargement de la ligne suivante (à la suite de celle restant dans le tampon) où l'on vérifie à nouveau la mise en correspondance avec l'expression régulière. Si la correspondance est établie, on ajoute un chevron (>) en début de ligne, à la suite de quoi la 1ère ligne du tampon est affichée (P), puis effacée (D) et on reprend l'exécution du script...
Le 2nd :
$ echo -e "foo\nfoo" | sed 'N;s/^/>/;s/\n/\n>/g'
>foo
>foo
$ echo -e "foo\nfoo" | sed 'N;s/^/>/Mg'
>foo
>foo
$
Dans cet exemple on s'emploie à démontrer l'utilité du flag "M" en n'utilisant qu'une seule expression pour rajouter un chevron en début de chaque ligne contenue dans l'espace de travail après l'appel de la commande "N".
Les commandes basiques 2
y
Transposition de caractères
(
intervalle d'adresse autorisée)
- La commande "y" permet de convertir n'importe quel caractère énuméré dans la chaîne caractère-source par son homologue, en lieu et place, se trouvant dans la chaîne caractère-destination.
L'emploi le plus courant pour cette commande est sans nul doute le remplacement des caractères accentués si cher à notre bonne langue française. En voici un petit exemple :
sed '
y/àâéèêëîïôöùûü/aaeeeeiioouuu/
y/ÀÂÉÈÊËÎÏÔÖÙÛÜ/AAEEEEIIOOUUU/
' fichier.txt
a\
text
Ajout
(
une adresse autorisée)
- Ajoute le texte "text" après la ligne mise en correspondance par son numéro de ligne, motif ou expression régulière, et avant la lecture de la ligne suivante. "text" correspond à une seule ligne de texte, qui peut néanmoins contenir des sauts de lignes précédés par des "\" (backslash).
sed '/Ligne n° 5/ a\
Bonjour
' fich.txt
i\
text
Insertion
(
une adresse autorisée)
- Insère le texte "text" avant la ligne mise en correspondance par son numéro de ligne, motif ou expression régulière. "text" correspond à une seule ligne de texte, qui peut néanmoins contenir des sauts de lignes précédés par des "\" (backslash).
sed '/Ligne n° 4/ i\
Bonjour
' fich.txt
c\
text
Échange
(
intervalle d'adresse autorisée)
- Échange la ligne mise en correspondance par le numéro de ligne, motif ou expression régulière par "text". "text" correspond à une seule ligne de texte, qui peut néanmoins contenir des sauts de lignes précédés par des "\" (backslash).
sed '/Ligne n° 2/,/Ligne n° 6/ c\
Annulé\
Pour cause\
de travaux
' fich.txt
r
fichier read
Lecture
(
une adresse autorisée)
- Lit le contenu de "fichier" dans l'espace de travail à la suite de l'adresse spécifiée. Il ne doit y avoir qu'un seul espace entre la commande et le nom du fichier. Tout ce qui suit cet espace, et ce jusqu'à la fin de la ligne, est considéré comme étant le nom dudit fichier. De ce fait tout espace (tabulation comprise) sera considéré comme faisant partie intégrante du nom. Si le fichier n'existe pas, aucun message d'avertissement ne sera émis ni sur la sortie standard ni ailleurs. Si le fichier ne se trouve pas dans le même répertoire d'où est lancée la commande, veillez à spécifier le chemin complet vers le fichier.
Vous pouvez vous en servir pour, par exemple, rajouter une signature en bas d'une série de fichiers. Pour illustrer ces propos, nous allons rajouter le contenu du fichier "signature.txt" à la fin de tous les fichiers correspondant au motif "fich*.txt" (
observez bien l'exemple qui suit et remarquez l'emploi du switch "-s". Amusez-vous à l'enlevez et notez la différence d'affichage) :
sed -s '$ r signature.txt' fich*.txt
w
fichier write
Écrire
(
une adresse autorisée)
- Écrit la ligne en cours de traitement dans le fichier spécifié à la suite de la commande "w". Tout comme la commande "r" (lecture), il ne doit y avoir qu'un seul espace entre la commande et le nom du fichier. Tout ce qui suit cet espace, et ce jusqu'à la fin de la ligne, est considéré comme étant le nom dudit fichier. De ce fait tout espace (tabulation comprise) sera considéré comme faisant partie intégrante du nom. Si un fichier du même nom existe déjà, il sera écrasé sans avertissement ni confirmation et ce à chaque invocation du scriipt. En revanche, si plusieurs instructions de la commande "w" sont appelées à écrire dans un même fichier depuis un script, chaque écriture est ajoutée à la fin du fichier.
Si le fichier n'existe pas il sera créé, même si le traitement est nul en sortie (aucune écriture envoyée)
Voici un petit scénario pour mettre cette commande en application. Depuis un fichier "adresses.txt" regroupant des noms de distributions associés à un code postal et sa ville de référence, extraire le nom de la distribution et sa ville associé et et l'envoyée dans un nouveau fichier portant le nom du département. Ce script nommé "foo.sed" sera appelé de la façon suivante :
sed -f foo.sed < adresses.txt
Contenu du fichier "foo.sed" :
#n
/\b31/{
s/[0-9][0-9]*//
w Haute-Garonne
}
/\b34/{
s/[0-9][0-9]*//
w Hérault
}
/\b66/{
s/[0-9][0-9]*//
w Pyrénées-Orientales
}
=
- Affiche le numéro de la ligne courante
sed -n '/motif/=' fichier
l [
N] --line-length=
N
Césure
(
intervalle d'adresse autorisée)
- Affichage des caractères non imprimable - N permet de spécifier la longueur de coupure de ligne désirée
sed -n l fichier # affichage caractères non imprimable
sed -n 'l 8' fichier # idem mais avec un retour à la ligne tous les 8 caractères
Les commandes avancées
Outre les commandes que nous venons de voir, Sed possède bien d'autres commandes, certes peu utilisées car moins bien connues et pour certaines pas très facile à assimiler et à mettre en application, mais qui lui permettent de pouvoir s'acquitter de certaines tâches sans avoir à pâlir de son simple statut d'outil ou de simple filtre.
Les commandes précédentes utilisées principalement le mécanisme suivant :
lecture d'une ligne du fichier d'entrée dans l'espace de travail à laquelle est appliquée chaque commande du script séquentiellement. Lorsque la fin du script est atteinte,, la ligne est alors envoyée sur la sortie standard, l'espace de travail est effacé, une nouvelle ligne est lue en entrée et le contrôle est passée à nouveau au début du script.
Avec les commandes qui suivent, nous allons voir comment inter-agir sur le déroulement du script, modifier le flux d'entrée sous certaines conditions, stocker des parties de lignes, tester des conditions, etc. etc...
Ces commandes peuvent se décomposer en 3 groupes :
- Les commandes multi-lignes (N,D,P)
- Les commandes utilisant la mémoire annexe (h,H,g,G,x)
- Les commandes de tests faisant appel à des étiquettes (:,b,t,T)
Les commandes multi-lignes
N
Next
Suivant
(
intervalle d'adresse autorisée)
- La commande "N" positionne le caractère "nouvelle ligne" (\n) à la fin du contenu de l'espace de travail et ajoute la ligne suivante du flux d'entrée à l'espace de travail. Si la fin du fichier d'entrée est atteinte, sed termine son exécution sans procéder au traitement d'une nouvelle commande. Le caractère "nouvelle ligne" incorporé dans l'espace de travail peut être matché par la séquence d'échappement "\n". Dans un espace de travail "multilignes", les méta-caractères "^" et "$" matchent respectivement le début et la fin de cet espace de travail et non pas les débuts et fins de lignes précédents ou suivants le caractère nouvelle ligne incorporé.
L'exemple qui suit cherche une ligne contenant le motif "C". Si celle-ci est trouvée, il ajoute la ligne suivante dans l'espace de travail et substitue le caractère fin de ligne "\n" pas un tiret entouré d'un espace de chaque côté :
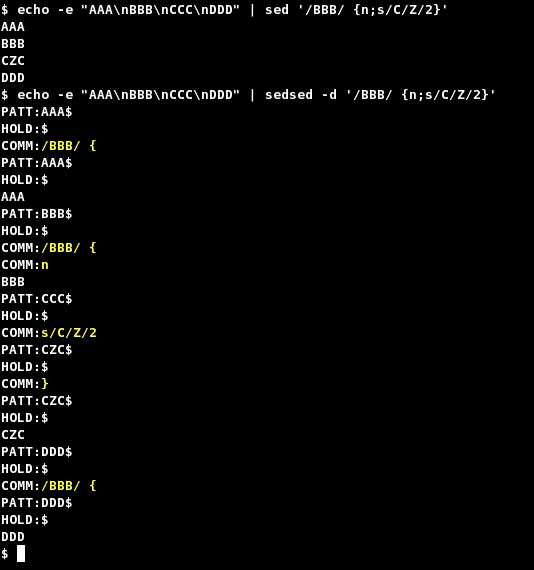
echo -e "A\nB\nC\nD\nE" | sed '/C/{N;s/\n/ - /}'
D
Delete
Effacer
(
intervalle d'adresse autorisée)
- La commande "D" efface le contenu de l'espace de travail jusqu'au 1er caractère délimitant une nouvelle ligne (\n). S'il reste encore des données dans l'espace de travail , un nouveau cycle est redémarré avec ce contenu (sans lire une nouvelle ligne en entrée), sinon un nouveau cycle est démarré avec la ligne suivante.
Pour illustrer l'emploi de la commande "D", je vais prendre un exemple donné dans l'excellent livre publié chez O'Reilly (
sed & awk, Second Edition) et qui résume très bien le mécanisme de cette commande à l'instar de la commande "d".
Le fichier de référence (commande_D.txt) :
Cette ligne est suivie d'une ligne vide
Cette ligne est suivie de 2 lignes vides
Cette ligne est suivie de 3 lignes vides
Cette ligne est suivie de 4 lignes vides
Fin du fichier

Pour des raisons de mises en page inhérentes à cet FAQ, dans le fichier ci-dessus, il n'y a que 3 lignes vides en dessous de la ligne "
Cette ligne est suivie de 4 lignes vides". Pensez à rajouter une 4ème ligne lors de vos essais avant d'expérimenter cet exemple.
Le but étant de regrouper les lignes vides consécutives en une seule. La commande "d" semble toute appropiée à cette tâche. Voyons un 1er script utilisant cette commande :
sed '
/^$/{
N
/^\n$/d
}' commande_D.txt
Pour se faire nous allons employer un motif nous permettant de matcher une ligne vide "/^$/". Dès qu'une ligne vide est trouvée nous demandons alors le chargement de la ligne suivante dans l'espace de travail avec la commande "N". Une fois cette ligne chargée, nous vérifions alors que le motif présent dans l'espace de travail correspond bien au motif "/^\n$/" (
un saut de ligne en tout et pour tout), et si c'est le cas, nous l'effaçons (commande "d"). Mais voilà, cette syntaxe ne marche que pour le cas ou le nombre de lignes est impair. Ceci s'explique par le fait que la commande "d" efface l'intégralité du contenu de l'espace de travail.
Effectivement, dès qu'une ligne vide est trouvée la ligne suivante est chargée (N), si cette ligne est vide, l'espace de travail est effacé (d) et un nouveau cycle est commencé avec une nouvelle ligne. Ainsi si cette nouvelle ligne (3ème) est vide, et la suivante non, alors la commande d'effacement (d) n'est pas appliquée et la ligne vide est affichée.
Par contre si nous remplaçons la commande "d" par son homologue "D" de cette façon :
sed '
/^$/{
N
/^\n$/D
}' commande_D.txt
Nous obtenons le résultat escompté. En effet, la commande "D" n'efface que la partie de l'espace de travail comprise avant le 1er caractère "/n" (saut de ligne), de ce fait si 2 lignes vides se retrouvent dans l'espace de travail, seule la 1ère ligne est effacée et le script redémarre avec le contenu de l'espace de travail (
une ligne vide), une nouvelle ligne est alors chargée, si elle n'est pas vide, les 2 lignes contenues dans l'espace de travail sont alors envoyées vers la sortie standard, sinon la 1ère partie est effacée et le scénario est répété...
En d'autres mots, si deux lignes vident se retrouvent dans l'espace de travail, seule la 1ère est effacée, si c'est une ligne vide suivie de texte, elles sont envoyées sur la sortie standard.
P
Print
Affichage
(
intervalle d'adresse autorisée)
- À l'instar de son homologue en minuscule qui affiche le contenu de l'espace de travail, la commande "P" affiche le contenu de l'espace de travail jusqu'au 1er caractère délimitant une nouvelle ligne (\n). Quand la dernière commande du script est atteinte, le contenu de l'espace de travail est automatiquement affiché sur la sortie standard (à moins que l'option "-n" ou "#n" n'ait été employée).
Les mémoires tampons
L'éditeur de flux Sed dispose de deux mémoires tampons qui permettent de stocker la (les) ligne(s) en cours de traitement.
Ces mémoires tampons sont souvent référencées sous l'appelation de "
pattern space" pour la mémoire principale, que l'on pourrait traduire par "espace de modèle" ou encore "espace de travail", et par "hold space" pour la mémoire secondaire, traduisible par "espace annexe".
L'espace de travail (
pattern space) est l'espace mémoire où sont maintenues les données (
la ou les ligne(s)) sélectionnées pendant leur durée de traitement.
L'espace annexe (
hold space) est l'espace mémoire où les données (
la ou les ligne(s)) peuvent être stockées temporairement.
Les commandes permettant de jongler entre ces deux espaces sont au nombre de cinq.
En voici un bref résumé :
- h Copie l'espace de travail dans la mémoire annexe
- H Ajoute l'espace de travail dans la mémoire annexe
- g Copie le contenu de la mémoire annexe dans l'espace de travail
- G Ajoute le contenu de la mémoire annexe dans l'espace de travail
- x Échange le contenu des 2 mémoires
À part la commande "x", les autres commandes marchent pour ainsi dire par paires et agissent pour chaque binome à la manière des redirections (>, >>, <,<<) des interpréteurs de commandes dans les shell comme "bash" ou "ksh". Leur rôle pourrait se traduire de cette façon :
- h > Écrase le contenu
- H >> Ajoute au contenu
- g < Écrase le contenu
- G << Ajoute au contenu
Voici une définition plus succinte de chaque commande pouvant affecter l'espace de travail :
h
hold pattern space
espace de modèle annexe
(
intervalle d'adresse autorisée)
- La commande h copie le contenu du motif courant (pattern space) dans la mémoire secondaire, écrasant le contenu précédemment copié si présent. Le tampon courant reste inchangé.
H
Hold pattern space
espace de modèle annexe
(
intervalle d'adresse autorisée)
- La commande H ajoute le contenu du motif courant (pattern space) au contenu de la mémoire secondaire. L'ancien contenu et le nouveau sont séparés par une nouvelle ligne matérialisée par le caractère "\n". Le tampon courant reste inchangé. Une nouvelle ligne (\n) est ajoutée à l'espace de travail même si celui-ci est vide.
g
get contents
copie le contenu
(
intervalle d'adresse autorisée)
- La commande g copie le contenu de la mémoire secondaire vers le motif courant, écrasant le contenu de celui-ci.
G
Get contents
ajoute le contenu
(
intervalle d'adresse autorisée)
- La commande G ajoute le contenu de la mémoire secondaire au motif courant. L'ancien contenu et le nouveau sont séparés par une nouvelle ligne matérialisée par le caractère "\n".
x
eXchange
échange
(
intervalle d'adresse autorisée)
- La commande x échange le contenu des deux mémoires tampons (principale et secondaire). Il faut savoir que la mémoire secondaire démarre son cycle avec une ligne vide. Si vous appliquez la commande "x" à la 1ère ligne d'un fichier, cette ligne est donc placée dans la mémoire annexe et est remplacée par le contenu de cette mémoire annexe, autrement dit une ligne vide. Sachez encore que suivant ce principe, la dernière ligne d'un fichier est placée dans la mémoire annexe mais n'est jamais restituée dans l'espace de travail et de ce fait ne sera jamais affichée à moins d'en faire une demande implicite.
Vous trouverez à la fin de ce documents quelques exemles commentés sur l'emploi des mémoires tampons de "sed", et pour commencer un petit exemple tout simple (toujours tiré de l'ouvrage des Éditions O'Reilly), très facile à comprendre, mais qui nous met en garde sur une des erreurs parfois incompréhensible qui peut arriver et nous faire tourner en bourrique ;-))
Une de ces erreurs justement concerne la mémoire annexe. Lorsque nous envoyons le contenu de l'espace de travail, et que nous procédons à divers traitements, et que ces traitements ne restituent le contenu de la mémoire annexe que sous certaines conditions, il peut arriver que ce contenu ne soit jamais restitué dans l'espace de travail et de ce fait, jamais envoyé vers la sortie standard...
En voici la démonstration.
Nous allons afficher la variable suivante :
$ A="1\n2\n11\n22\n111\n222"
$ echo -e "$A"
1
2
11
22
111
222
et demandé à "sed" d'intervertir les lignes commençant par "1" avec celles commençant par "2".
Pour ce faire nous allons commencer par matcher les lignes commençant par "1", copier le contenu dans la mémoire annexe avec la commande "h", puis vider l'espace de travail, c'est le rôle de la commande "d". À ce moment là, le contrôle est renvoyée au début du script, où une nouvelle ligne est chargée (avec un "2"), la 1ère compraison (/1/) échoue, mais la seconde (/2/) est vraie, donc le contenu de la mémoire annexe est ajoutée à l'espace de travail, qui contient alors "2\n1$". Comme nous sommes arrivés à la fin du script, le contenu de l'espace de travail est affiché et remplacé par l'entrée suivante (11) et le script recommence, et ainsi de suite...
Voilà le script :
echo -e "$A" | sed '
/1/{ # si le motif est présent
h # le copier dans la mémoire annexe
d # effacer le contenu de la mémoire principale
}
/2/{ # si le motif est présent
G # ajouter le contenu de la mémoire annexe
}'
et l'affichage final :
2
1
22
11
222
111
Comme nous l'avons vu, tout se passe bien dans le meilleur des mondes. Mais qu'en serait-il si nous glissons un "333" à la place du "22" ? Et bien justement c'est ce qu nous allons voir.
Tout d'abord, l'affichage de la nouvelle variable :
$ A="1\n2\n11\n33\n111\n222"
$ echo -e "$A"
1
2
11
33
111
222
Et son passage à la moulinette par "sed" :
$ echo -e "$A" | sed '/1/{h;d};/2/{G}'
2
1
33
222
111
Et bien comme vous pouvez le voir, l'affichage du "11" est passée à la trappe ! Et pourquoi donc ? Et bien, comme cela a été dit en début de cet exemple, tout bonnement parce que le contenu de la mémoire annexe n'est restitué dans l'espace de travail que si et seulement si un motif contenant un "2" est rencontré. Dans le cas contraire, le script continue son bohnomme de chemin, autrement dit, il affiche la ligne présente dans l'espace de travail (33) et passe le contrôle au début du script qui charge la ligne suivante (111), ligne qui satisfait la condition du 1er motif (/1/) et de ce pas envoie son contenu dans l'espace annexe, écrasant de ce fait les données présentes (11).
Donc, attention lors de l'élaboration de certains scripts de bien restituer le contenu de la mémoire annexe.
Étiquettes
Les étiquettes (
label) permettent de sauter à un emplacement précis à l'intérieur même d'un script. Sed possède trois commandes prévues à cet effet. Une commande inconditonnelle "b" comme "branchement" et deux commandes conditionnelles "t" et "T" comme "[tT]est".
La syntaxe pour désigner une étiquette se limite à placer en début de ligne (
pour un script) deux points suivis d'une lettre (
ou suite de lettres afin de former un mot, cette dernière étant vivement recommandée pour une meilleure lisibilité du code).
:etiquette
Cette étiquette sera alors appelée dans le script à l'aide des commandes "b", "t" ou "T".tout simplement en faisant précédée son nom par la commande désirée :
b etiquette
t etiquette
T etiquette
Branchement inconditionnel
b
branch
(
intervalle d'adresse autorisée)
- La commande b permet de transférer inconditionnellement l'exécution du script à l'emplacement indiqué par l'étiquette fournie en argument. Si aucun argument n'est fourni, la commande renvoie à la fin du script. La commande en cours de traitement est alors affichée sauf si l'option "-n" était active et le script reprend son exécution avec la prochaine ligne du flux d'entrée.
Exemple de branchement inconditionnel
Branchement conditionnel
t
test
(
intervalle d'adresse autorisée)
- La commande t permet de transférer conditionnellement l'exécution du script à l'emplacement indiqué par l'étiquette fournie en argument si une commande de substitution a réussi sur la ligne en cours de traitement ou sur le dernier branchement conditionnel. Si aucun argument n'est fourni, la commande renvoie à la fin du script.
Exemple de branchement conditionnel 1
T
test
(
intervalle d'adresse autorisée)
- La commande T permet de transférer conditionnellement l'exécution du script à l'emplacement indiqué par l'étiquette fournie en argument si une commande de substitution a échoué sur la ligne en cours de traitement ou sur le dernier branchement conditionnel. Si aucun argument n'est fourni, la commande renvoie à la fin du script.
Exemple de branchement conditionnel 2
SED - The Stream EDitor - Part II
Suite Part II =>
SED - The Stream EDitor - Part II
Lire la suite
Sed - Introduction à SED - Part III »
Publié par
jipicy -
Dernière mise à jour le 16 novembre 2009 à 16:40 par marlalapocket



 Gsed 4.0 et supérieur
Gsed 4.0 et supérieur
 Voici deux façons de procéder :
Voici deux façons de procéder :




 Ce document est une introduction à la pratique et à l'utilisation de l'éditeur de flux "SED", qui essaie de couvrir certaines fonctionnalités assez méconnues, pour ne pas dire "quasi inconnues", qui font de "SED" un outil indispensable dans la boîte à outils de tout Linuxien désireux de se rompre aux maniements et aux arcanes du traitement de fichiers via une console et un shell.
Ce document est une introduction à la pratique et à l'utilisation de l'éditeur de flux "SED", qui essaie de couvrir certaines fonctionnalités assez méconnues, pour ne pas dire "quasi inconnues", qui font de "SED" un outil indispensable dans la boîte à outils de tout Linuxien désireux de se rompre aux maniements et aux arcanes du traitement de fichiers via une console et un shell.